
Runhouse 0.0.12: rh.Module, Streaming, and too much more
Buckle up, this is less a release blog post and more a wild ride through the Infra API Wonka Factory (prepare to see some $*%t, Charlie). We’ll talk through the innocent motivations which turned into upending half of Runhouse’s core execution model, and the gaggle of awesome new features which fell out.

CEO @ 🏃♀️Runhouse🏠
Innocent Product Motivations
As a reminder, Runhouse provides a unified programming, collaboration, and lineage interface into your compute and data infra, across many infra types and platforms. It’s composed of Runhouse OSS, a homogenous, accessible programming interface into arbitrary infra, and Runhouse Den, a lineage, collaboration, and governance layer. Obviously, Runhouse OSS needs to provide state-of-the-art performant and flexible interfaces out of the box.
Around early July, there were a few simple truths we knew we needed to act on:
- In-Python pinning - Loading objects from disk or sending them over the GPU bus can take a long time, so holding them in Python memory is crucial for many applications. For large models, these load times can add minutes to inference latency. As of 0.0.10, we were relying too heavily on Ray’s object store to persist objects on the cluster, which led to serialization overhead when pinning and fetching large objects, and broke our ability to properly hold an object in GPU memory over time.
- Process overhead - As of 0.0.10, we were launching each remote function call in a new process via ray.remote to support running in distinct environments (e.g. conda). This led to process launch and inter-process communication overhead, increasing function call latency.
- Streaming - Supporting generators and streaming back results from the cluster one by one is crucial for LLM applications, where interactively displaying tokens as they’re generated is the gold-standard UX. However, it is not a trivial feature. Ray, one of the most widely used systems for hosting and serving LLMs, only added streaming results as recently as July 2023.
- Logs everywhere - We want running code with Runhouse to feel as close to local execution as possible. Previously, remote stdout and logs were streamed back to the console when remote functions were called, but not for other types of calls to the cluster (e.g. installing packages). Surfacing logs and stdout everywhere would improve the interactivity and debuggability of users’ code.
- Remote methods - Calling a method remotely on an object in the cluster’s object store would be super cool.
Performance: A Cleverer Ray Architecture Cratered Latency
After many experiments and some guidance from Ed Oaks at Ray, we found the best way to address pinning and process overhead was to create “Servlet” Ray Actors, each of which mediates all activities in a particular environment (e.g. installing packages, putting and getting objects, running functions). The Cluster’s HTTP server simply accepts requests and passes them into the appropriate servlet for the request’s env, and creates a new one for the env if needed. Because each Ray Actor lives in its own process, each can have an object store where objects truly persist in Python, and the Cluster HTTP server, other actors, or even other programs on the cluster can load that Servlet Actor by name to interact with it. Because activities within the same env are now in the same process, there’s far less interprocess overhead, and function calls in the same env don’t require any process launch overhead. Latency crashed to the floor compared to Runhouse 0.0.10. Here’s a fun interaction we had with a discord user shortly after this landed in main:
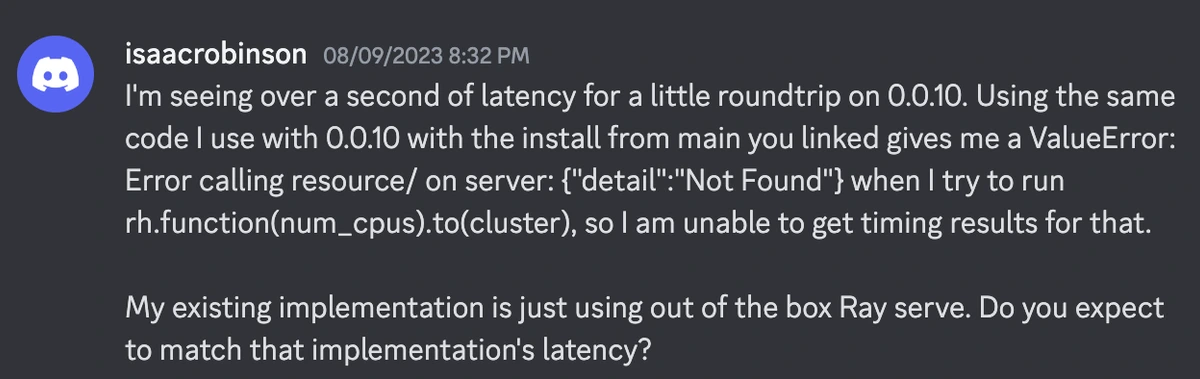
After updating the cluster's Runhouse version:


A new level of environment flexibility, thanks to Ray
What’s amazing about using Ray for these servlets is how easily functions and objects in completely different environments can interact. AI moves very quickly so accidental BC breakage is common, and we’ve all had the experience of needing a very specific set of library versions for one model and a different set of exact versions for another in the same program. Runhouse functions can easily call functions or request objects in other envs, and programs can natively traverse many envs with practically no mental overhead - just send one function to one env and the other to another. Right now we support bare metal and Conda envs, but soon we’ll add Docker envs and python venvs too. All of this is made possible by Ray.
preproc_env = rh.env(reqs=["tokenizers==0.10.3", "sentencepiece"]) preproc_fn = rh.fn(preproc_fn).to(gpu, env=preproc_env, name="llama2-preproc") preproc_fn(raw_data_path, batches_path, num_workers=32, batch_size=8, max_seq_len=512) fine_tuning_env = rh.env(reqs=["transformers", "accelerate", "bitsandbytes==0.40.2"], conda_env={"name": "llama2-finetuning"}) training_fn = rh.fn(training_fn).to(gpu, env=fine_tuning_env, name="llama2-training") training_fn(batches_path, output_path, model_id="meta-llama/Llama-2-13b-chat-hf", batch_size=8, gradient_accumulation_steps=4, learning_rate=1e-4, warmup_steps=1000, weight_decay=0.01, num_train_epochs=1, fp16=True)
Caroline wired up Servlets to support Conda Envs and environment variables, so you can expect full parity with the existing Envs from 0.0.10.
rh.here for pinning and debugging
Another fun API we’ve introduced via this work is rh.here, which returns the cluster it's called on, or “file” if called locally. This allows us to easily interact with the object store, e.g. to quickly pin or get an object, but also via a python interpreter for debugging:
Pinning objects to GPU memory works better than ever, and calling remote functions feels like the GPU is attached to your laptop. This shell and Python interpreter are running locally on my laptop, but the inference function and model are on my remote cluster:
I felt a little queasy about our previous APIs for pinning objects to cluster memory (rh.pin_to_memory() and rh.get_pinned_object(), now deprecated), and I’m much happier with rh.here.put() and rh.here.get() to interact with the object store directly on the cluster.
rh.Module, a powerful new primitive
Runhouse’s bread and butter has been putting functions on compute and calling them remotely. But we soon saw limitations:
- More code lives in classes than functions. If we want Runhouse to truly be zero-onramp and dispatch existing code without any migration (or creating function wrappers), we need a way to send a class to the cluster to call methods on it.
- As Runhouse applications grow more complex, we frequently find them expanding from a single remote function to several, passing around some state via the object store. It felt obvious that these functions and state would make more sense as methods and attributes of a class instance.
- As we introduced new remote-aware abstractions in Runhouse, we added new methods and endpoints to our on-cluster HTTP server to support their functionality. This looked like it may quickly get out of hand, and meant users couldn’t extend Runhouse with their own abstractions.
The ability to call methods on remote objects stored on the cluster is a natural solution, and it encapsulates almost everything we do when we interact with remote compute. For example, we previously had a dedicated install_packages HTTP endpoint on the cluster, but this can simply be represented by putting the env object into the cluster’s object store and then calling env.install remotely.
Previously, many classes in Runhouse had to include branching and distinct behavior for cases when the object is local, i.e. is being used on the system where it lives, and when the object is remote, i.e. represents a remote object on a cluster elsewhere. If we can call a method on an object remotely, classes can simply define their local behavior in their instance methods, and those methods can be called locally or via HTTP call if needed. This leads to not only dramatically simpler but also more powerful code, as remote behavior can include factors which can only be observed locally on the cluster, like CPU count, whether something is installed, or whether a file exists.
User-defined Modules allow you to rapidly extend Runhouse
Instantly we realized this opens many doors. Nearly all Runhouse objects - Functions, Blobs, Tables, Envs, etc. - can be defined based on local behavior, and then used remotely via a single call_model_method endpoint on the cluster. That endpoint can support all the capabilities we want out of remote function calls, like streaming generator results, streaming logs, async, saving results, queueing, provenance, and more, but they apply across any interaction with the cluster. So that’s what we did, and the results are magic. At a basic level we got what we wanted from this release - streaming remote logs back across all of our interactions with the cluster, streaming generator results, and calling remote methods - but now making any class into a Runhouse .to-able object is instantaneous, and we extended that power to users.
rh.Module subclasses for creating infra-traversing tools
We’ve captured this behavior in a new Runhouse primitive we call Module, meant to be reminiscent of PyTorch’s nn.Module. You’ll instantly recognize the similarities in the APIs:
import runhouse as rh class KV(rh.Module): def __init__(self): super().__init__() self.data = {} def put(self, key, value): self.data[key] = value def get(self, key, default=None): return self.data.get(key, default)
This new KV class now has superpowers:
if __name__ == "__main__": my_cpu = rh.cluster("rh-cpu", instance_type="CPU:2") my_kv = KV().to(my_cpu, name="my_kvstore") my_kv.put("a", list(range(10))) import requests res = requests.post("http://localhost:50052/call/my_kvstore/get", json={"args": "a"}) print(res.json()) # prints out [0, 1, 2, 3, 4, 5, 6, 7, 8, 9] my_kv.save()
You can even save, load, and share it via Den:
If you’ve ever had to set up a remote Redis store for a few servers to interact with (including wrapping it in an API, maybe Docker compose, setting up auth, etc.), you know how much boilerplate this can eliminate.
rh.module factory for making any existing class remote-able
Remote objects are not unprecedented. Ray, Modal, and others offer this model quite successfully and inspired much of the API. But Runhouse enables remotable classes with existing, unchanged code, via the rh.module factory method (note the lowercase m). This means you don’t need to migrate existing code to adopt Runhouse or fragment your codebase for different infra scenarios, and further, you can do crazy things like this:
import runhouse as rh from sentence_transformers import SentenceTransformer if __name__ == "__main__": gpu = rh.ondemand_cluster(name='rh-a10x', instance_type='A10:1').up() GPUModel = rh.module(SentenceTransformer).to(gpu, env=["torch", "transformers", "sentence-transformers"]) model = GPUModel("sentence-transformers/all-mpnet-base-v2", device="cuda") text = ["You don't give 'em as a joke gift or wear them ironically or do pub crawls in " "'em like the snuggy. They're not like the snuggy."] print(model.encode(text))
We’re going from importing sentence_transfomer to a remote Embedding service on my own GPU in 3 lines of code, and the model is even pinned to GPU memory! There’s no hidden magic code here which is pre-baked to set up an embedding API but won’t extend to custom use cases. Runhouse is entirely AI-agnostic, so this works for any Python class.
Keep in mind that we’re not just letting you define an API quickly here like Next.js or FastAPI, we’re actually building you this production API from scratch inside your own infra or provider account. Running the code above:
The fact that every Module method comes pre-baked with a rich feature set means streaming generator results, HTTP support, async methods, low-latency mode, streaming logs, saving results, and much more are built in. You can have a fancy streaming Llama 2 service in minutes:
There are probably a dozen other new features which fell out of this work, such as caching environment installs to speed them up, and richer support for passing remote objects into functions, but we can’t cover them all here. We’ll publish subsequent blog posts talking about how those fit into more thematic directions for Runhouse. Stay tuned.
New docs!
Matt Kandler, our fantastic Front-end Engineer, gave the house a much-needed paintjob in the form of a new docsite (run.house/docs). He devised an awesome system for auto-generating docs in React that we imagine must be useful to other OSS projects, and Josh even added a script which allows you to generate the resources for every existing branch in your repo. If you’re an OSS maintainer and interested in the deets please contact us!
Manual Cluster Setup Path
If you’re having trouble with cluster setup, we now support a manual setup path to bypass various steps which you may want to do yourself (e.g. port forwarding, syncing your code onto the cluster, etc.). We’ve also added a convenient runhouse restart CLI command which you can run on the cluster to terminate both the HTTP server and Ray server on the cluster, along with any in-progress executions, and start them anew.
Coming up
Sagemaker - Cloud AI Platforms like AWS Sagemaker offer serverlessness and container support which are simpler to manage than a dedicated Kubernetes cluster or EC2 fleet. Further, some users don’t have quota or permission to spin up new cloud instances, and instead only have access to compute through an AI platform. Josh has been working on Sagemaker Cluster support for the last month, and it’s being released as an alpha presently. Feel free to give it a try and please let us know what you think!
Revamped Secrets - Runhouse’s secrets support both in OSS and Den is relatively simple. We have a big opportunity to provide super simple secrets syncing for our users across many environments and providers. Further, we can support cluster secrets in a way that will make clusters more natively collaborative through Den. Caroline is leading this revamp.
Kubernetes - At long last, we are adding support for pulling Runhouse sub-clusters out of an existing Kuberenetes cluster/namespace. One day soon, a typical ML engineer or Data Scientists will need to know very little or nothing at all about Kuberenetes or Docker. The challenge here is largely designing the solution in a way which is most durable to the extreme diversity of K8s rigs, and making the auth and setup requirements as minimal as possible. One of our newest engineers, Rohan, is leading this effort.
Stay up to speed 🏃♀️📩
Subscribe to our newsletter to receive updates about upcoming Runhouse features and announcements.
Read More


“LudicrouslyFastAPI:” Deploy Python Functions as APIs on your own Infrastructure

