
A PyTorch Approach to ML Infrastructure
Platform overhead occupies 50-75% of ML engineers’ and researchers’ time. Runhouse is a PyTorch-like unified interface to solve that.

CEO @ 🏃♀️Runhouse🏠
In my experience, every machine learning project marches one-way from iterable and debuggable Python toward rigid, boiler-plate-ridden platform code. The march is toward more powerful infra - training on greater compute, testing on realer data, or deploying for live consumption - but the increasingly constrained debugging interfaces, translation into platform-specific APIs, and hour or longer iteration loops take velocity to a crawl.
As the product lead for PyTorch, I was baffled and frustrated by the universality of this phenomenon. PyTorch had produced a unified modeling language across research and production, OSS and private, and even different hardware types, and yet users would still spend 50-75% of their time trying to wrestle that code into their infra - in dependency hell, distributed hell, or CUDA hell; packaging their code into docker containers, CLIs, orchestration DAGs, or inference endpoints; and debugging from afar in notebooks, Slurm, or orchestrators. Users were frustrated that writing the modeling code was only a fraction of their time compared to learning these systems, debugging them, and translating from one to another.

I spent years talking to hundreds of PyTorch users about these problems. They take many forms, but overwhelmingly stem from “fragmentation” or “silos” in ML, or the breakdowns as you move code across different compute and data infra. To be more specific, they fall in three categories:
- Research and Production silos: Researchers have Pythonic, iterable, and easy-to-debug interfaces for fast experimentation, but are at arm’s length from the real compute and data infra used to power production. Meanwhile, production code runs on powerful infra but is hard to debug and has poor developer experience. Translating research into production (R2P) can be a 6-12 month activity, while there might not even be a path that takes production ML back to local Python for further development (P2R).
- External and Internal silos: Adapting external code for your own infra, or packaging your code to share with others, is a months-long undertaking. Simply not knowing what infra was used underneath some code you find in OSS or elsewhere in your company can lend it inaccessible to you.
- Infra silos: Every compute or data system has its own APIs and behavior, and even moving between systems within the same provider (e.g. EC2 → Sagemaker → EKS) can take months of code translation. The different visibility and management systems (or lack thereof) across providers and on-prem is a tentpole problem for many VPs of Data and ML. Models and data are lost on random servers, lineage and provenance is limited, resources exist without clear owners, and little is shared between teams.

Why can’t we have nice things?
Over the last few years the broader software world has arrived at a golden age of developer experience, but two essential differences drove ML off that road.
Hardware-specificity
Docker largely put the final nail in the coffin of code importability in traditional software. But ML code is highly hardware-specific and optimized, down to the CUDA minor version and GPU layout, so if you move your code to new hardware it will break no matter how many containers it’s wrapped in. If you stumble upon some Javascript code published with a dockerfile, you could probably run it within the hour. In ML you’d probably spend the hour Googling if this model runs on V100s, A10s, or A100s, and take weeks to get it running if it’s distributed or written for different hardware than yours.
Hardware-heterogeneity
A single ML program often requires multiple types of hardware, and it’s expensive and wasteful to occupy that hardware for the life of the program. For this we use ML pipeline DAGs, but they have an interesting backstory. From 2012-2015, ML at big tech companies was CPU-centric and geographically distributed. They needed a way to ship ML algorithms to wherever on earth data were and run reproducibly. A pipeline of container images is a great way to do that, and Google, Facebook, and Uber widely announced their pipeline-centric ML platforms. Nowadays, everyone runs their code near the GPUs and the containers can’t simply be sprinkled on pools of datacenter CPU compute, but we’ve kept the pipeline DAGs. We take a massive iterability and debugging hit in exchange for running different pieces of the program on different hardware. DAGs are crucial and great for certain things - scheduling, caching results, monitoring, and handling failures - but they’re meant to do so for fully working programs. Imagine debugging a SQL statement by continually rerunning the full pipeline it’s contained in, instead of getting it working and then scheduling it in the pipeline. That’s what we do in ML.
Unified interfaces solve silos
The stories of notebooks, pipelines, and PyTorch point in the right direction for solving ML fragmentation: unified interfaces. Many researchers would prefer not to exclusively work in notebooks, but are happy for them to serve as a consistent high-iteration interface whether they run on Databricks, Sagemaker, Vertex, Azure ML, Kubeflow, etc. Similarly, orchestrators give the relief of abstracting away the compute underneath each node (e.g. on-prem, cloud VMs, Kuberenetes, serverless). PyTorch broke down silos between research/production and internal/OSS by providing a unified modeling interface.
So what if there were a PyTorch for the infra too?
Runhouse: A unified interface into ML infra
Over the last 8 months, I’ve teamed up with some old friends, Josh and Caroline, to work on Runhouse, an OSS unified Python interface into compute and data infra, built on the following principles:
Infra Agnostic: ML platform teams sprung up everywhere from 2020-2022, and they want direct control of the infra. They don’t want to be disintermediated from the underlying infra, forgo control over which systems and tools they can use, or adopt a one-size-fits-most platform which introduces a new silo.
A la carte: The onboarding lift (and subsequent vendor fatigue) in ML tooling is insane. Everyone is tired of 9 month trial integrations. Incremental adoption and not needing to migrate data, compute, or code is critical. A 10 minute time-to-wow is ideal.
Python-generic: Many ML tools have been built with assumptions about how AI is done which go stale within a year or two as the field progresses. Being Python-generic but batteries-included for AI is much more durable, and avoids walling off non-AI teams.
How it works
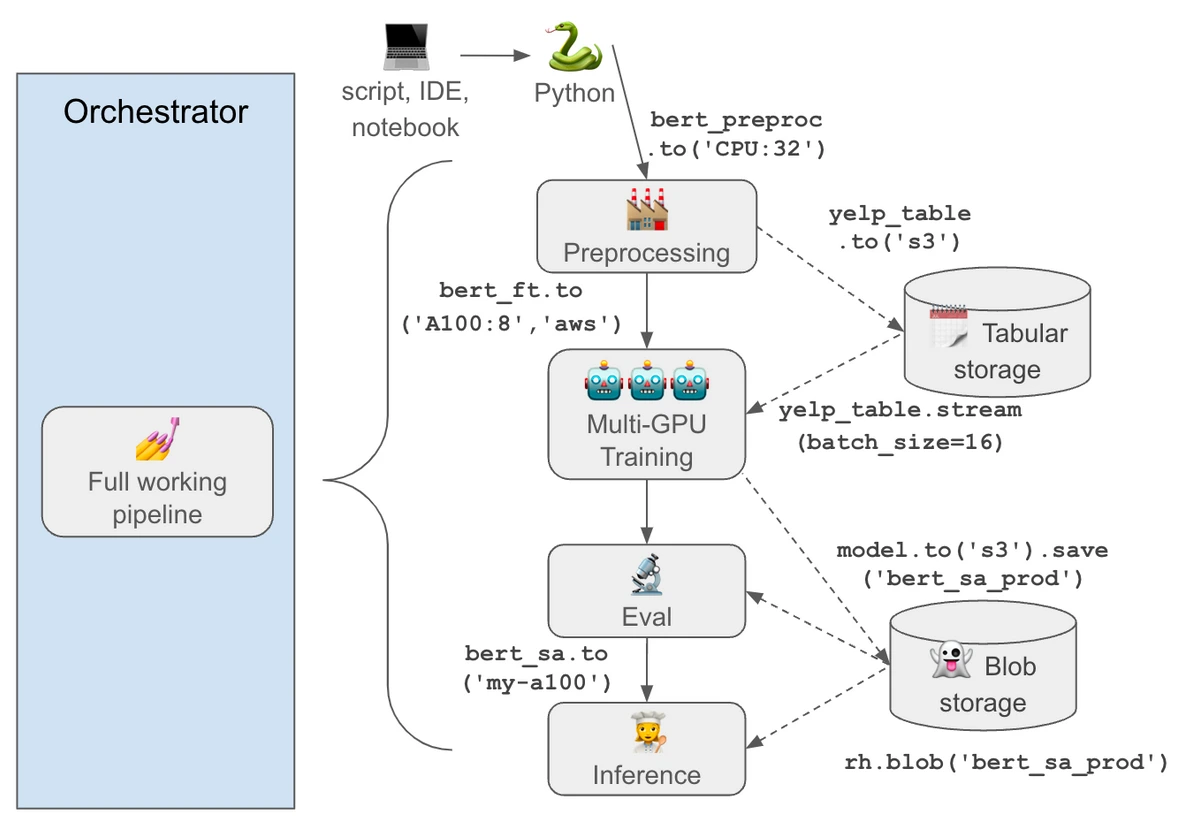
Just as PyTorch lets you send a model .to("cuda"), Runhouse enables hardware heterogeneity by letting you send your code (or dataset, environment, pipeline, etc) .to(“cloud_instance”, “on_prem”, “data_store”...), all from inside a Python notebook or script. There’s no need to manually move the code and data around, package into docker containers, or translate into a pipeline DAG.
gpu = rh.cluster("rh-a100", instance_type="A100:1", provider="cheapest") inference_fn_gpu = rh.function(inference_fn).to(gpu, env=['./', 'torch']) result = inference_fn_gpu(prompt='A hot dog made of matcha powder.') result.show()
I can send my function to an existing IP or pull instances fresh from any major cloud provider (AWS, GCP, Azure, Lambda, and more), all from inside my notebook or script. When I call this remote function, my inputs are sent to the server, the function is run, and the results are sent back to me. The function essentially became a service I can call over and over. If you think about the difference between what we call an “ML pipeline” and a simple Python script, the pipeline is a living system which is run repeatedly and updated over time. So doesn’t it make more sense to modularize it into smaller living systems, i.e. microservices, rather than slice it into docker images which each contain non-reusable glue code? That way, I can selectively send out the functions which need to run on remote infra, and leave the glue code where it is.
# Create microservices for pipeline components, sending them to desired cluster to be run on preproc_data = rh.function(fn=preproc_data).to(cpu, env=["datasets", "transformers"]) fine_tune = rh.function(fine_tune).to(gpu, env=["reqs:./"]) eval_model = rh.function(eval_model).to(gpu) with rh.run(name="exp_20230612", path="~/rh/logs/exp_20230612"): train_data, test_data = preproc_data(remote_raw_data) # runs on cpu trained_model = fine_tune(pretrained, train_data) # runs on gpu accuracy = eval_model(trained_model, test_data) # runs on gpu
You can think of Runhouse as an “eager-mode orchestrator,” comparable to a DAG based pipeline as PyTorch is to Tensorflow. It can traverse the same flexible, abstracted set of compute, but is executed by your local Python, and doesn’t need to be “submitted for execution” to a remote engine. It’s debuggable, DSL-free, and has a simple and predictable execution flow. You can use your orchestrator for what it’s good at, and slot your fully working program into it with minimal bundling or debugging (the services run exactly the same whether called from your notebook or orchestrator!).
There was once a claim that beyond a certain “scale” translating into pipeline DAGs is simply necessary. Directly disproving that claim, Uber recently announced that they’ve rearchitected their entire ML platform to call into the infra in Python in this way, instead of breaking up their code into pipeline DAGs. Runhouse uses this same approach built on Ray, but delivers it in a simple, incrementally adoptable interface that anyone can pick up and try.
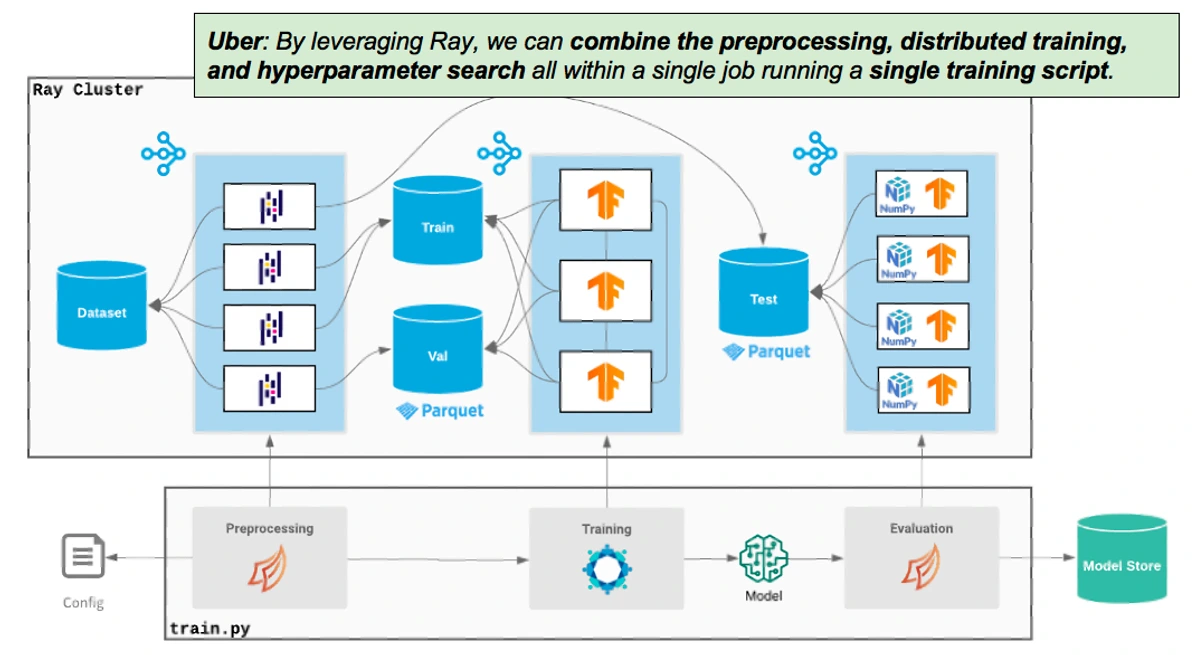
(image from 2021 Uber blog post)
We emphasize that Runhouse is an interface rather than a platform because it layers on top of your own existing compute and provider accounts. Your existing groups, quota, permissions, and networking remain unchanged, and we simply unify the surface with which you interact with them. That way, you can adopt it incrementally without vendor approvals, being disintermediated from the underlying infra, or creating a new silo. Data Scientists, Researchers, and ML Engineers can try Runhouse without needing to request vendor approvals or asking an infra team to integrate it into “the stack.”
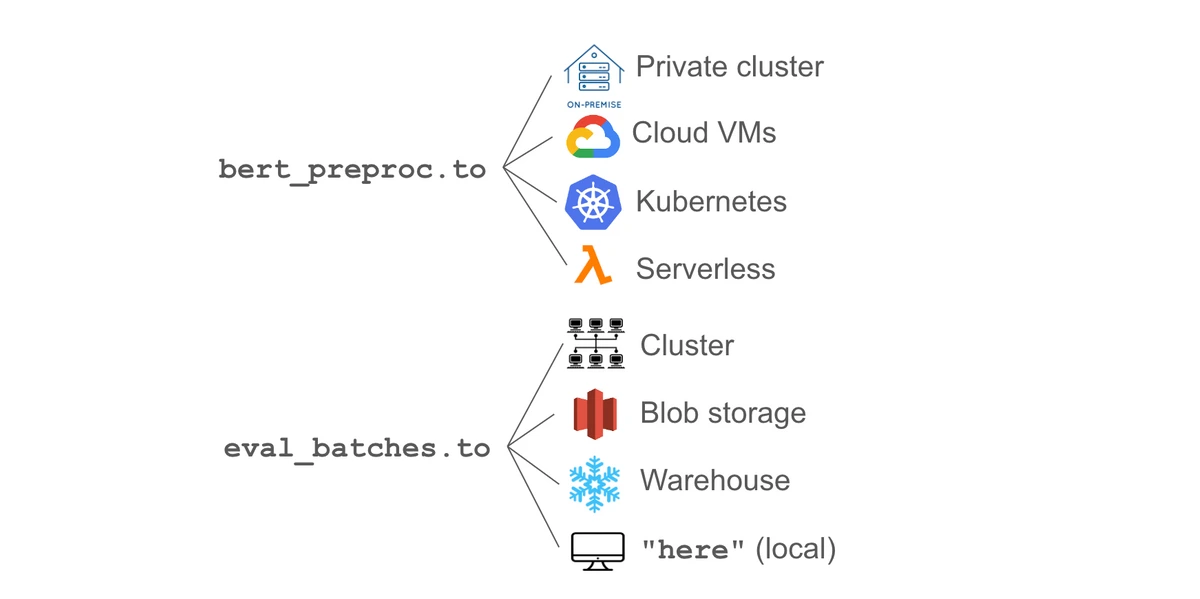
OSS reproducibility & accessibility
The ability to program your infra from Python is especially powerful for OSS maintainers. Instead of publishing dozens of CLI commands and README instructions to reproduce a program, OSS maintainers can publish their actual multi-hardware code, including the exact hardware and dependencies. This alone can improve reproducibility, but by supporting a flexible set of infra behind the APIs, anyone can pick up the code and run it on their own infra. I can say firsthand that the top source of issues and questions for many AI OSS maintainers is setup, and many repos try to include detailed instructions for different cloud providers or usage scenarios. With Runhouse, OSS maintainers can build setup scripts and integrations once, and through Runhouse’s abstractions support all the major cloud providers, on-prem, and a continually growing set of infra underneath. In fact, Runhouse is used within Hugging Face Transformers, Accelerate, and Langchain in exactly that way.
Runhouse Den: Making infra multiplayer
We certainly can’t adapt code to any hardware, nor are we claiming to solve dependency hell. But ideally, once code is working on particular hardware, many can benefit. If you’ve sent your BERT fine-tuning function to 4 GPUs, gotten it running and optimized the speed and memory consumption, Runhouse allows you to save and persist that microservice for further use. You can load and call the service from your pipeline to make it even lighter and easier to maintain, and know that it’s calling the same exact code on the same exact hardware as your notebook did. And further, you can share it with your team or company as a common BERT fine-tuning service, which can be versioned and updated over time. The same can be said for other cloud resources like your preprocessed table, model checkpoint, or inference function.
Runhouse includes a free DNS-like service called Den which allows this type of multiplayer resource sharing and management (only sharing a minimal amount of metadata while the resources stay in your own doors), think Google Drive for your ML resources. Google spent years convincing everyone to migrate their files to the cloud to facilitate the sharing and accessibility of Google Drive. Compute and data resources already live in the cloud, so it’s crazy that we can’t already share and access them just as easily. Den provides this accessibility and sharing layer across infra and providers, allowing ML teams to build a common ML corpus across research and production.
What Runhouse is not
We want to be clear that Runhouse is not a system that you need to migrate to from whatever infra or tooling you use today. It doesn’t have a clear analogue in the ecosystem and is largely complementary to the existing stack. For example, you can use Runhouse with your orchestrator by writing and iterating on your heterogeneous ML programs in Python and then slotting them into an orchestration node in full to schedule and monitor them. You can save Runhouse resources to your experiment management system to improve reproducibility and ease of retrieving the original resources. Runhouse can also allow you to more easily try and onboard to new compute platforms (e.g. Anyscale, Sagemaker, Modal, etc.) by giving you a consistent interface and convenient defaults across paradigms which minimize change to your code.
Building in the open
Runhouse is in the relatively early stages considering the long list of infra we’d like to support. We feel it’s crucial that the project is built transparently and in the open to maximize its applicability to the broadest range of usage scenarios and keep it low-lift to adopt. You can find our currently supported infra types and providers in our README, as well as upcoming additions. If you’re aligned with the vision above (or vehemently oppose it) we strongly welcome input, contributions, and opportunities to partner, and can be reached in Github, over email (first name at run.house), or in our Discord.
Stay up to speed 🏃♀️📩
Subscribe to our newsletter to receive updates about upcoming Runhouse features and announcements.
Read More

Better GPU Cluster Scheduling with Runhouse
Actors for Kubernetes
