Dev and Prod Workflows
Moving between research/development and production is straightforward with Kubetorch. Even though Kubetorch lets you run code identically anywhere, there are two different principal concerns to optimize for:
- Local development: Fast development and experimentation, where local edits to your repo and any necessary packages to install or setup commands to run are all able to propagate quickly to your remote compute running at scale on Kubernetes.
- Production: Execution is exactly reproducible, with all program code, dependencies, and environment setup already pre-installed on your Docker image.
Development with Fast Iteration Loops
During development, the goal is near-instant feedback on changes. As we note in Dev Workflow, you can resync local changes to remote in less than 2 seconds.
You also need to modify the environment without rebuilding Docker images for new libraries.
Kubetorch’s Compute class accepts an image argument for execution. In iterative development,
you can start with a base image and add installs or commands interactively. Chaining commands
to kt.Image() lets you extend images without rebuilding, repulling, or relaunching pods,
keeping your iteration loops fast.
Research to Production
With Kubetorch, any program you develop locally is instantly production-ready, with no translation or handoff required. Kubetorch separates the “what” of a program (its code, compute requirements, and image) from the “how” and “when” (scheduling, retries, and notifications). Development and production share the same underlying code, and production is simply wherever you choose to run it.
This can be as simple as running your program on a scheduler in GitHub Actions or GitLab CI. Alternatively, you can package your program into a Docker image with Kubetorch, which can run anywhere with access to your Kubetorch Kubernetes cluster.
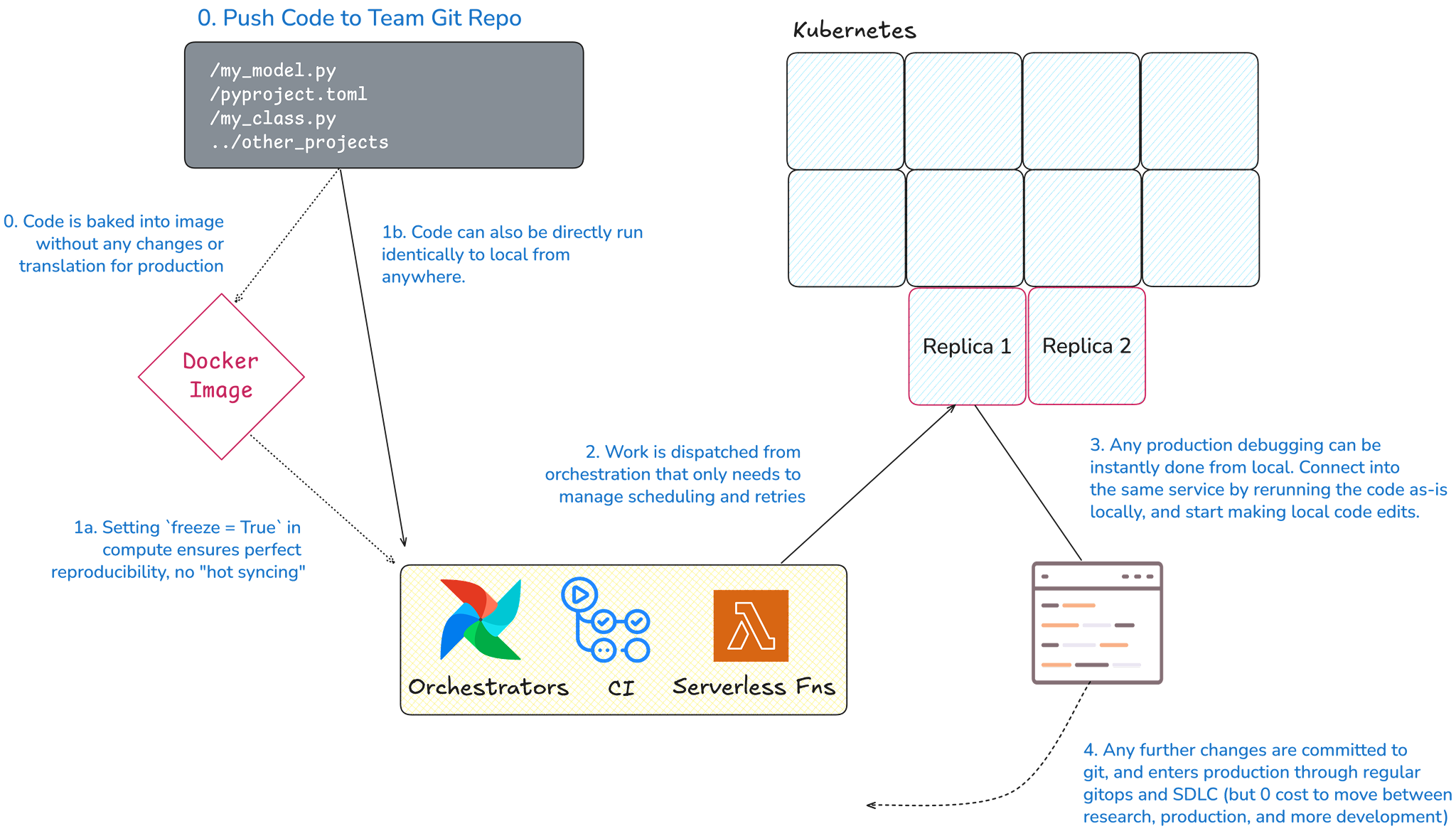
There are a few other considerations for production that we think teams should consider for best-practice development.
Branching by Environment
Teams using Kubetorch frequently use environment variables to specify
whether code is running in production mode. For instance, here, we'd
assume that the env var "ENVIRONMENT" will be set to "PROD"
in the production environment / CI.
import os prod = os.environ.get("ENVIRONMENT") == "PROD"
Image Definition
In production, you likely want to ensure that all dependencies, environment variables, and setup steps have already been baked into the image itself. As an example, running pip installs that depend on public package registries would not guarantee reproducibility, even if you pin the version.
if prod: base_image = kt.Image(image_id="prod_docker_image") else: base_image = kt.Image() .from_docker("prod_docker_image") .sync_package("path/to/local/other_package") .pip_install("other_package") .pip_install("pip_package==0.2.0") .set_env_vars({"var: VAR"})
Compute Definition and Flag
In the Compute construction, there is a flag freeze to differentiate
between a development and research setting. The freeze flag signals
to freeze the state of the compute config, and not sync over any local
code changes or make updates to the base Docker image. This
guarantees what is in the Docker image already will run. As noted earlier,
in the development case, with freeze=False or unset, when we call .to(compute),
the local train_fn, will be synced over onto the pod in under 2 seconds.
compute = kt.Compute(cpus=".1", image=base_image, freeze=prod)
Creating and running the function is identical in either case.
Summary
To aggregate all the steps described above, this is simple code branching for research and production:
import kubetorch as kt from my_repo import train_fn if __name__ == "__main__": prod = os.environ.get("ENVIRONMENT") == "PROD" if prod: base_image = kt.Image(image_id="prod_docker_image") else: base_image = kt.Image(image_id="prod_docker_image") .sync_package("path/to/local/other_package") .pip_install("other_package") ... # any other differing setup steps to override compute = kt.Compute(cpus=".1", image=base_image, freeze=prod) remote_train = kt.fn(train_fn).to(compute)
Production to Research
Making research-to-production easy also makes production-to-research simple. This is important for two reasons: debugging and enhancements.
For debugging, reproducing a production error locally is straightforward. Check out the production code, hit the bug, and make changes immediately. Once fixed, push the updates through CI.
For enhancements, any team member, even a new intern, can check out the code and start improving training or pipelines locally. Everything is captured in code, so there are no hidden steps or rework required.