System Overview
Kubetorch enables ML research and development on Kubernetes, across training, inference, RL, evals, data processing, and more, in a deceptively simple and unopinionated package. It does this without disintermediating you from the underlying infrastructure, so you can always punch through abstractions to finely control behavior or use any tooling you like from the rich Kubernetes ecosystem.
Most "ML platforms" provide opinionated point-solutions for individual stages of ML - e.g. a training launcher, notebooks, inference endpoints, etc. - but these abstractions inevitably go stale in 1-2 years as ML evolves. Kubetorch is different because it precisely solves the fundamental gaps in Kubernetes for ML, which unlocks the complete set of activities an ML team needs in both development and production, while allowing teams to continue using their existing code, tools, automation, and workflows.
How It Works
In general, ML on Kubernetes entails deploying Python code onto compute (pods of many shapes and configurations) and calling it. Kubetorch allows you to "burst out" any subroutine in Python to your compute cluster, calling your code on remote containers as if they were a local process pool.
Just like the general-purpose nature of PyTorch - running Python on GPUs - this basic structure applies from development through production for online (e.g. inference), offline (e.g. training), and everything in between (e.g. RL):
- Need to debug a distributed training? Just run your training loop on n containers with m GPUs each
- Need to migrate from OpenAI to self-hosted? Just drop in vLLM and run it on some autoscaling GPUs from inside your FastAPI app
- Need to preprocess some data before training? Launch some Ray or Spark compute, run your preprocessing on it, and stream it out to your training job or feature store
- Need to launch code sandboxes for an agent? Just launch n containers with .1 CPU each and gVisor and run your agent inside
- Need to fine-tune your agent with GRPO? Just launch your existing inference service and some sandboxes to generate rollouts, launch some training GPUs to back-propagate through the trajectories, sync the weights with Kubetorch GPU data sync, and repeat.
- Need to do embarrassingly-parallel processing? Send your processing function to autoscaling compute, call it async thousands or millions or times, and asyncio.gather the results.
Kubetorch does this via a highly accelerated deployment system for Kubernetes, allowing you to deploy, call, scale, and teardown subroutines so fast that you can do so on the fly inside Python. It provides both low-level deployment primitives that you can use directly, and higher level Python APIs that deliver an elegant, programmatic experience that anyone can use:
import kubetorch as kt from my_repo.training_main import train train_compute = kt.Compute(cpus="2", gpus="1") remote_train = kt.fn(train).to(train_compute) result = remote_train(lr=0.05, batch_size=4)
In this simple, high-level example, Kubetorch:
- Packages your function and dependencies into resource manifests (pods + service endpoint) and a dockerfile
- Launches your compute resources, or patches them if already present
- Syncs your code and any container updates to the compute, distributing to all pods via fast data sync
- Routes your call through to the compute via the service endpoint
- Returns the result, with logs and exceptions propagated back to your client
Critically:
- Subsequent
.to()calls after the initial launch distribute code quickly and only differentially apply your changes, so a one-line code change or additional pip install redeploys in seconds, not minutes. - This code will run identically from outside the cluster during development, and from diverse environments like CI, orchestration, or inside the cluster in production.
- This is regular Python, with no local runtime (which can fail) or special initiation sequence. It can be dropped deep inside existing code for a subroutine to wield scalable cluster compute.
- This example represents a relatively simple flow launching one service and calling it, but wildly complex sequences and flows can be composed together - launching services from inside other services, passing service stubs around, branching resources depending on dev/CI/prod flags, sharing services from multiple different workloads, and more.
Caveats on Customization
It's important to understand that the above is a very high-level, abstracted example. You're probably looking at it, wondering, "but can I control x"? The answer is generally yes:
- You can fully customize the image the code serves on - bring your own image, bring your own unbuilt dockerfile (including local dependencies, which will sync up automatically), and/or lightly add dependencies through our kt.Image Python API. You can use accelerated serving engines (and their images) like vLLM, Triton, TensorRT, TorchServe, etc.
- You are not limited to Kubetorch's built-in compute types. "Compute" in Kubetorch is simply any Kubernetes resource which bears pods. You can bring existing pod-bearing manifests (e.g. Kubeflow PyTorchJob, LeaderWorkerSet, KServe, JobSet, etc.) and use them with the Kubetorch APIs.
- You can fully customize the manifest YAML of the compute or services Kubetorch launches, both with simple passthrough arguments in kt.Compute (e.g. labels, annotations, secrets, volumes, etc.), and by manipulating the compute manifest directly.
- Kubetorch does not need to launch and manage the compute. You can launch your own arbitrary compute resource, start the Kubetorch server on the pods, and dispatch work to them like you would any other Kubetorch compute resource.
- You do not need to use the Python APIs to utilize Kubetorch's fast deployment. You can run
kt applyas a drop-in replacement forkubectl apply(with added support for passing an unbuilt dockerfile) to deploy resources with fast differential deployment and data/code broadcast. - You can easily export Kubetorch resources to be runnable directly on Kubernetes without Kubetorch.
- You can use any networking, observability, scheduling, DevOps, security, or other Kubernetes tooling you like, just as you would with regular Kubernetes resources.
What's Inside
Helm Charts
Kubetorch installs cleanly into your cluster via Helm:
helm install kubetorch kubetorch/kubetorch -n kubetorch --create-namespace
The base installation includes:
- Compute lifecycle controller and routing layer
- Data store and sync services
- Lightweight, ephemeral log and metrics streaming services
Optional Integrations
Kubetorch integrates with existing cluster infrastructure for additional capabilities:
| Integration | Purpose |
|---|---|
| Knative | Support for scale-to-zero autoscaling as a Compute type |
| KubeRay | Support for Ray workloads as a Compute type |
| GPU schedulers (e.g., Kueue, NVIDIA KAI) | Gang scheduling, workload prioritization |
| Persistent storage | Shared datasets, checkpointing |
| Custom ingress | Domain routing, external access |
See the installation guide for details.
Python Client and CLI
Users interact with the Pythonic interface through three core primitives:
| Primitive | Maps To | Purpose |
|---|---|---|
kt.Compute | Pod pool + K8s Service | Define resources (CPUs, GPUs, memory) and scaling |
kt.Image | Container environment | Define dependencies, synced live to pods |
kt.fn / kt.cls / kt.app | Deployed application | Your code serving inside the compute pods |
These primitives are covered in detail in Core Python Primitives.
What Kubetorch Precisely Solves
Kubernetes's design around scalable web systems fundamentally mismatches with ML in four key ways:
- Static application specification - Kubernetes wants applications to be neatly pre-packaged as YAML and container images, deployed as a roughly static application (maybe with some autoscaling). ML by comparison, includes complex, heterogeneous workloads which must be able to deploy and use new containers/resources programmatically. For example, you can't run an RL training by simply kubectl applying a Kubeflow PyTorchJob, a vLLM inference service, and some code sandboxes. Or conversely, you can't catch a CUDA OOM and reduce your batch size or increase your training resources from inside a Kubeflow PyTorchJob or Airflow pipeline.
- Hard in-vs-out of cluster boundary - Kubernetes's auth and networking models are based off a hard assumption that "human work" happens strictly outside the cluster and production work happens strictly inside. Unfortunately, ML teams don't have GPUs and distributed compute attached to their laptops, and need to do development and iteration using cluster resources.
- Slow packaging and deployment - Kubernetes has relatively slow packaging and deployment, essentially tearing down and rebuilding application resources from scratch upon any change. In ML, cold-starts are often expensive - loading down massive images, models, data, etc. - and making a one-line code change can take 20-40 minutes to needlessly teardown and recreate the resources in full. Queuing systems for GPU sharing exacerbate this, because tearing down the application usually also means re-entering the allocation queue.
- No built-in data layer - transferring data in and out of the cluster, or distributing data scalably within the cluster is essentially unsolved in Kubernetes. These activities happen constantly in ML, including code distribution, weight syncs, data syncs, and more, often to thousands of pods at once.
Architecture Layers
Kubetorch is built as four layers, each solving one of the problems above. The layers build upon one another but can be used independently:
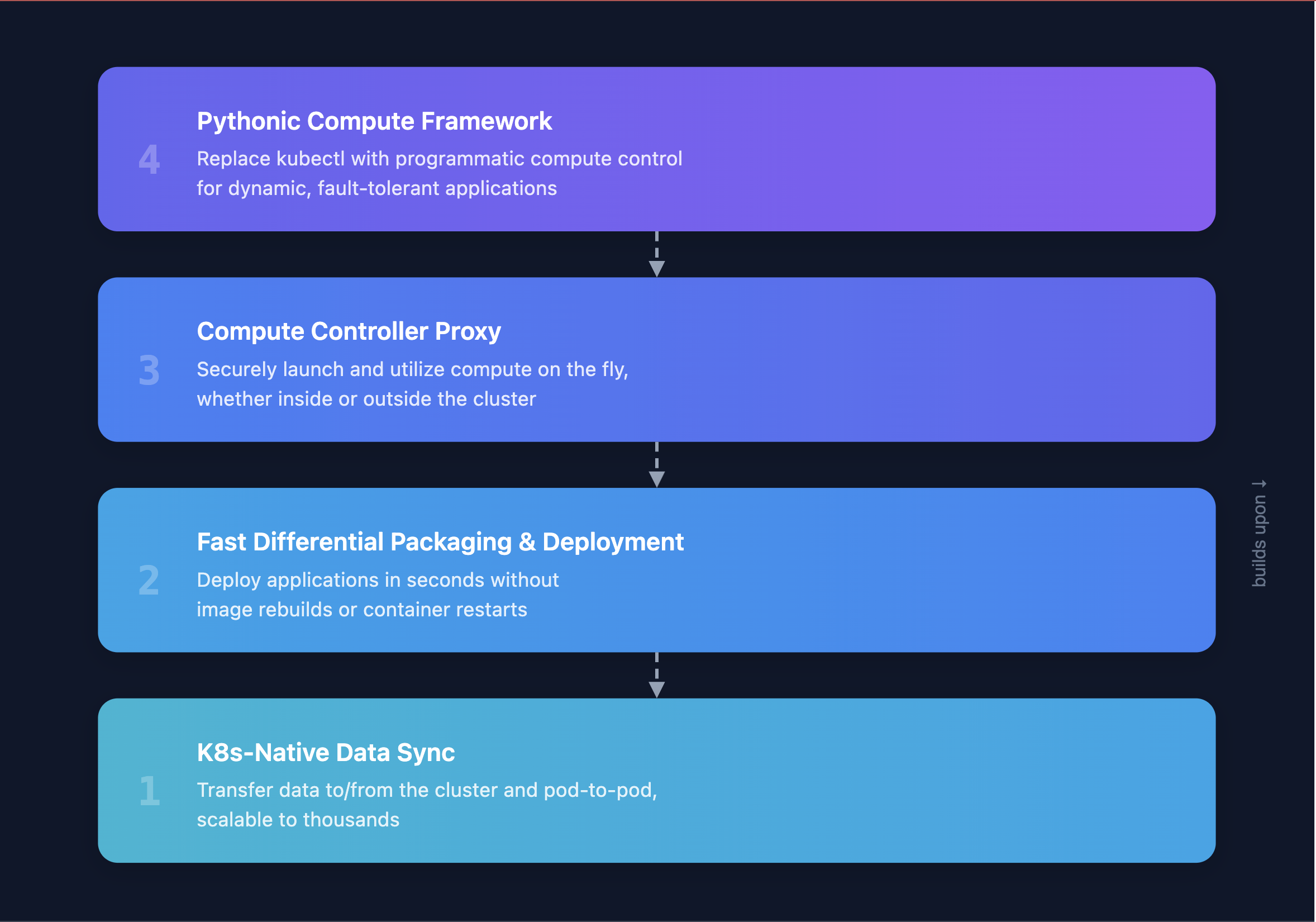
We'll review these layers from the bottom up, as each builds upon the one below it.
Layer 1: K8s-Native Data Sync
The foundation solves Kubernetes' lack of a built-in data layer. Kubetorch provides a Kubernetes-native data store enabling:
- Differential transmission: Fast sync of filesystem data (code, files) to/from the cluster, sending only what changed
- Peer-to-peer broadcast: Scalable distribution within the cluster (e.g., 1000 nodes receiving a code update simultaneously during redeployment)
- GPU data sync: Direct GPU memory transfers for distributed training
This layer makes code syncing fast enough that you don't need to rebuild containers for every change. You can use it within Kubetorch programs, or on its own. See Data Store for details.
Layer 2: Fast Differential Packaging & Deployment
This layer solves Kubernetes' slow packaging and deployment cycles. Built on the data store, it enables on-the-fly resource deployment with intelligent caching:
- Diff-aware updates: If you change one line in a Dockerfile or make a one-line code change, redeploying applies only that diff to existing resources, without tearing down containers or rebuilding images
- No rebuild cycles: Eliminates the 20-40 minute repackage/redeploy wait that plagues ML development on K8s
- Dynamic launching: Resources can be created, updated, or torn down in seconds, which makes it practical to launch compute on the fly from within a program
- Rational queue behavior: Kubetorch holds resources in place while you're using them, so you don't need to constantly create super-priority carveouts in your queueing system (e.g. Kueue) for high-priority development.
This solves the "execute by deployment" problem where ML practitioners wait endlessly because they can't test locally without GPUs or distributed compute.
Layer 3: Compute Controller Proxy
This layer solves Kubernetes' hard in-vs-out of cluster boundary for both compute lifecycle activities, which are generally authorized outside the cluster, and service calling, which is generally authorized inside the cluster. It's a controller and proxy service providing centralized, secure compute launch and call access whether inside or outside:
- Location-agnostic: Deploy, call, scale, and tear down applications whether inside or outside the cluster
- Dynamic compute flexibility: Workloads can spawn additional compute, scale themselves, or coordinate with other services - despite Kubernetes' model of privileged "human work" happening outside the cluster
- Proxy layer: Route calls to applications inside the cluster from external clients, so development doesn't require being inside the cluster. Composite applications like inference pipelines can call live endpoints even during local development. If you're familiar with Ray or Spark's serialization limitations which require all code to be executed on the head node, this layer eliminates that limitation in Kubetorch.
This restores the local development experience to ML and allows programs to run identically in development, CI, and production.
The controller launches and manages standard Kubernetes resources and manifests via the Kubernetes APIs and scheduling, so it works natively with any scheduling, admission, autoscaling, or lifecycle controls or tooling you already have in place.
Layer 4: Pythonic Compute Framework
This layer solves Kubernetes' static application specification model. It is a Pythonic compute framework which is unobtrusive to your application code, and replaces sequences of kubectl commands with programmatic compute control:
- Native Python: Replace tribal wisdom of complex build and deployment sequences with readable, version-controlled code
- Dynamic orchestration: Build RL training loops, multi-stage pipelines, or inference services that programmatically launch and tear down compute for maximum resource efficiency.
- Zero-cost Abstractions: You can always control the compute resources in Kubetorch down to the underlying manifests and YAML, so you're not limited by simplistic abstractions like "cpus=n, gpus=m".
- Scalable, stable, and flexible: Kubetorch inherits Kubernetes' scalability and flexibility directly - it uses K8s scheduling, autoscaling, networking, and resource management rather than creating limited facsimiles of them
- Platform compatible: Platform teams can leverage the massive K8s ecosystem, including existing cloud integrations, DevOps tooling, observability stacks, security policies, and networking configurations
- Durable execution: Applications can manage their own compute lifecycle, surviving failures and scaling on demand. Catch a CUDA OOM and resize your resources from inside your code.
System Flow
This section describes how Kubetorch's components interact at runtime. Understanding this flow is helpful for debugging, platform integration, and advanced customization.
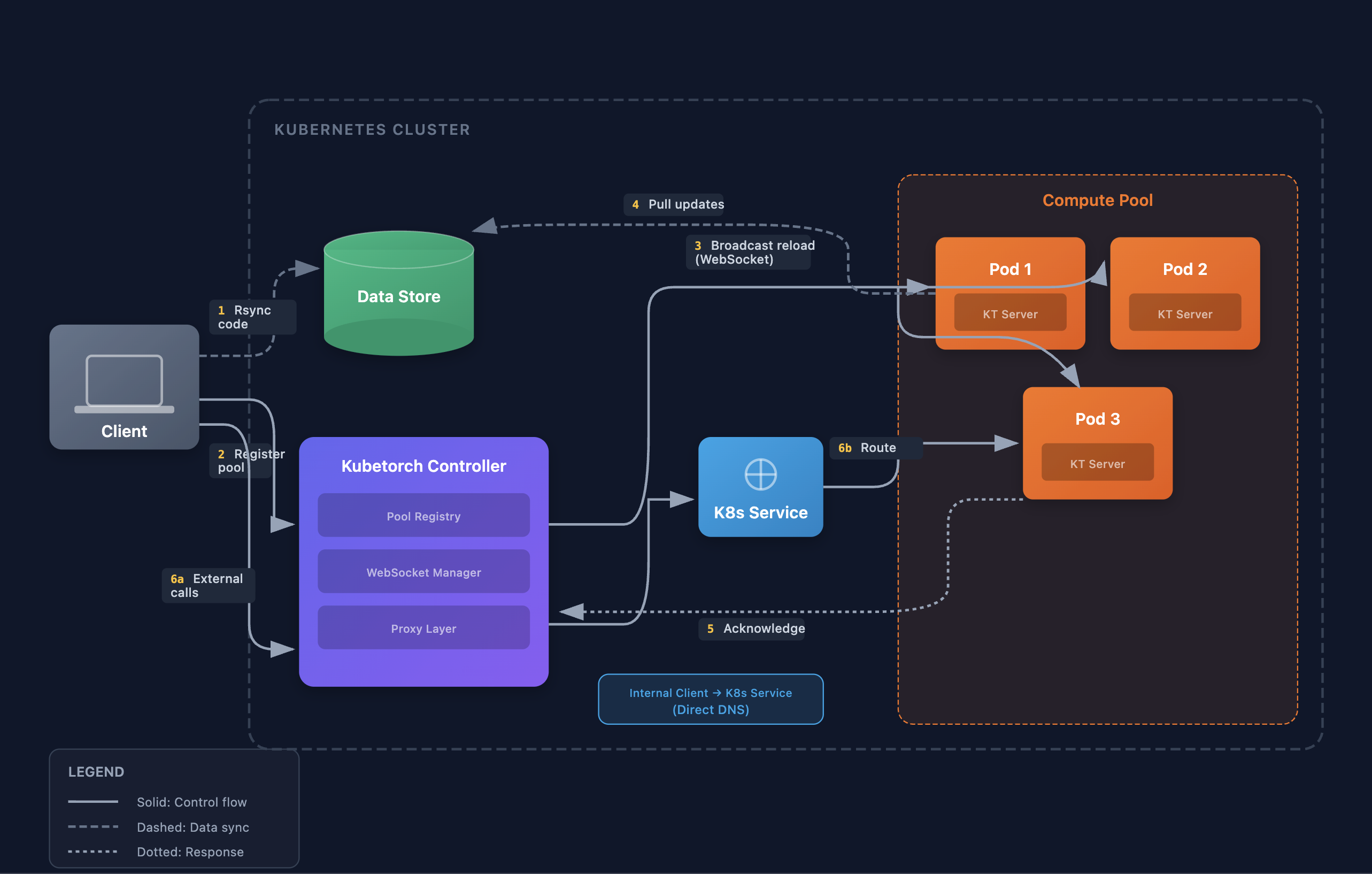
1. Compute Launch
Compute pods are launched in one of three ways:
- Standard: The Kubetorch client calls the controller's
/deployendpoint, which applies K8s manifests - CLI:
kt applyapplies manifests directly with fast differential deployment - BYO (Bring Your Own): User creates their own K8s resources, starting the Kubetorch server on them
Each pod runs the Kubetorch HTTP server, which handles user code serving/execution, redeployment (including image updates), log and metrics streaming, peer-to-peer data syncing, and distributed coordination.
2. Pod Registration
On startup, each pod establishes a persistent WebSocket connection to the Kubetorch controller:
Pod → WebSocket → Controller {pod_name, pod_ip, namespace, service_name, request_metadata: true}
The controller tracks all connected pods by their service name (compute pool). This connection enables push-based updates without polling for fast redeployment at scale.
3. Pool Registration and Metadata Delivery
When a user deploys code via .to():
- Code Sync: Local code and dependencies are rsynced to the Kubetorch data store
- Pool Registration: Client calls the controller with module info, dockerfile configuration, and pool metadata
- Broadcast: Controller stores the pool configuration and broadcasts a reload message to all connected pods for that service via WebSocket
For BYO compute, pods connect before the pool is registered. They receive a "waiting" status and begin serving
once the user registers the pool via .to().
4. Pod Update
When pods receive a reload message:
- Apply Metadata: Set environment variables (module name, file path, init args, etc.)
- Image Setup: Pull code updates from the data store, run any new pip installs or dockerfile steps
- Reload Callable: Clear the callable cache, terminate existing subprocess workers, create fresh workers
- Acknowledge: Send acknowledgment back to controller
The controller waits for all pods to acknowledge before returning success to the client. This ensures the entire pool is ready before calls are made.
5. Service Calls
When users call a deployed function or method:
Client → Controller Proxy (external) or K8s Service DNS (internal) → Pod
- External calls (from outside the cluster): Route through the controller's proxy layer
- Internal calls (from inside the cluster): Route directly via Kubernetes service DNS
The pod's HTTP server receives the call and dispatches it to subprocess workers via the configured execution supervisor. Execution modes include:
- Standard: Single-pod execution with subprocess isolation
- Load-balanced: K8s Service distributes calls across replicas
- Distributed: Coordinator broadcasts to all workers (SPMD pattern for PyTorch, JAX, etc.)
Results, logs, and exceptions propagate back to the client.